Seeding your database
Populate your database with initial data for reproducible environments across local and testing.
When you run supabase init we create an empty seed.sql file in the root of the supabase folder. You can use this to populate your database with seed data.
What is seed data?
Seeding is the process of populating a database with initial data, typically used to provide sample or default records for testing and development purposes. You can use this to create "reproducible environments" for local development, staging, and production.
Using the seed file
The seed.sql file is run every time you run supabase start or supabase db reset. Seeding is done after all the database migrations have been run. As a general rule, you should not add schema statements to your seed file, only data.
You can add any SQL statements to this file. For example:
Generating seed data
You can generate seed data for local development using Snaplet.
If this is your first time using Snaplet to seed your project, you'll need to setup Snaplet
for your project with npx snaplet setup, and follow the interactive prompts. snaplet setup
will look at your database and its structure, and use it to generate the configuration files
and assets needed by @snaplet/seed.
Suppose you have a database with the following schema:
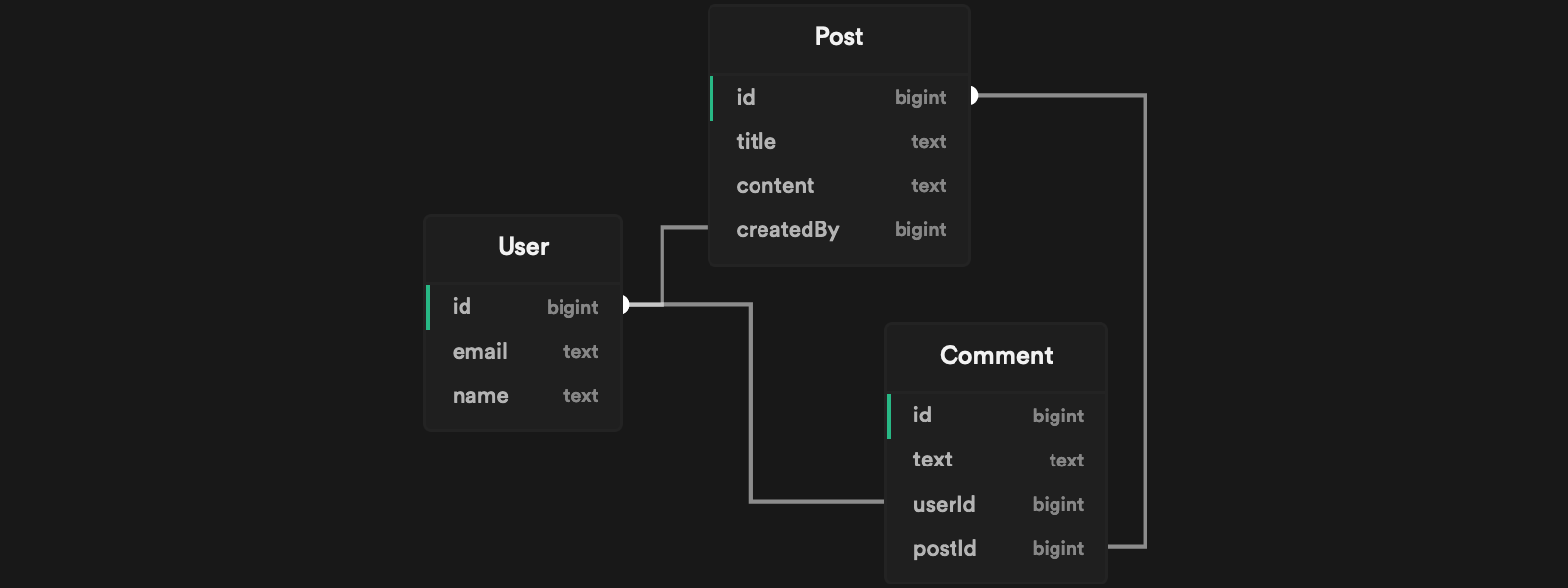
You can use the Snaplet configuration file seed.mts to define the values you want to generate. For example
- A
Postwith the title"There is a lot of snow around here!" - The
Post.createdByuser with an email address ending in"@acme.org" - Three
Post.commentsfrom three different users.
Running npx tsx seed.mts > supabase/seed.sql generates the relevant SQL statements inside your supabase/seed.sql file:
_18-- The `Post.createdBy` user with an email address ending in `"@acme.org"`_18INSERT INTO "User" (name, email) VALUES ("John Snow", "snow@acme.org")_18_18--- A `Post` with the title `"There is a lot of snow around here!"`_18INSERT INTO "Post" (title, content, createdBy) VALUES (_18 "There is a lot of snow around here!",_18 "Lorem ipsum dolar",_18 1)_18_18--- Three `Post.comments` from three different users._18INSERT INTO "User" (name, email) VALUES ("Stephanie Shadow", "shadow@domain.com")_18INSERT INTO "Comment" (text, userId, postId) VALUES ("I love cheese", 2, 1)_18_18INSERT INTO "User" (name, email) VALUES ("John Rambo", "rambo@trymore.dev")_18INSERT INTO "Comment" (text, userId, postId) VALUES ("Lorem ipsum dolar sit", 3, 1)_18_18INSERT INTO "User" (name, email) VALUES ("Steven Plank", "s@plank.org")_18INSERT INTO "Comment" (text, userId, postId) VALUES ("Actually, that's not correct...", 4, 1)
Whenever your database structure changes, @snaplet/seed will need to be regenerated so that it is
in sync with your new database structure. You can do this by running npx snaplet generate.
For more information, check out Snaplet's seed documentation